作业①:
1)
gitee链接:
https://gitee.com/zxbaixuexi/scrapy_homework/tree/master/作业2/1
要求:在中国气象网(http://www.weather.com.cn)给定城市集的 7
日天气预报,并保存在数据库。
代码:
import requests
import sqlite3
from bs4 import BeautifulSoup
#创建DB类用以操作sqlite
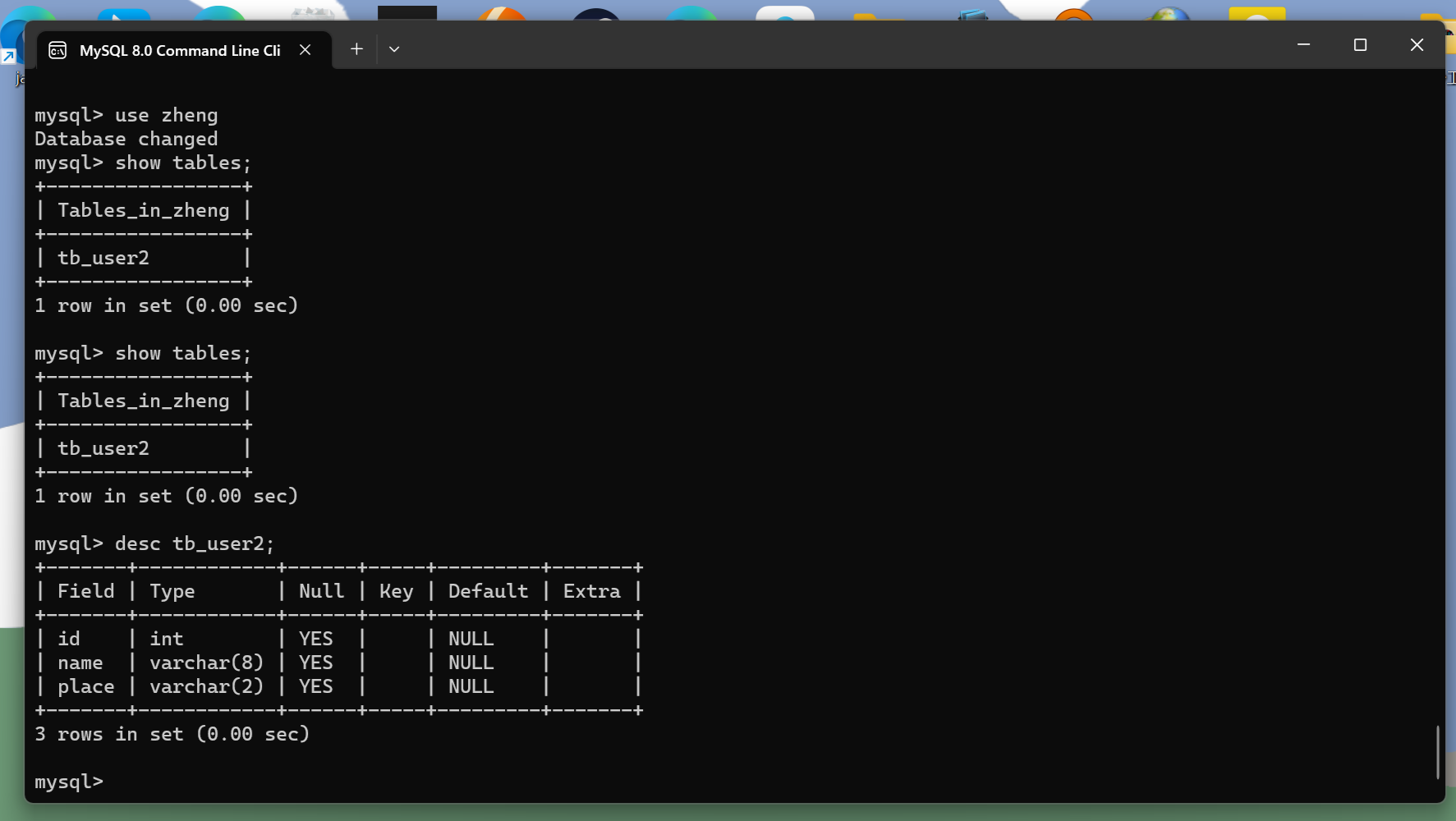
class DB:#创建空的weather.dbdef open(self):self.connection=sqlite3.Connection('weather.db')self.cursor=self.connection.cursor()try:self.cursor.execute('create table weather(序号 int,region vachar(16),date vachar(64),info vachar(100),tmp vachar(16))')except:self.cursor.execute('delete from weather')#关闭weather.dbdef close(self):self.connection.commit()self.cursor.close()#插入数据def insert(self,number,region,date,info,tmp):self.cursor.execute('insert into weather(序号,region,date,info,tmp) values(?,?,?,?,?)',(number,region,date,info,tmp))#将weather.db的所以数据输出def show(self):self.cursor.execute('select * from weather')rows=self.cursor.fetchall()print('序号','地区','日期','天气信息','温度',sep='\t')for row in rows:print(row[0],row[1],row[2],row[3],row[4],sep='\t')#weatherforest类爬取数据并存入weather.db
class weatherforest:#初始化def __init__(self):self.url = r'http://www.weather.com.cn/weather/'self.citycode = {'北京': '101010100', '上海': '101020100', '广州': '101280101', '深圳': '101280601'}#记录数据的条数,用以作为编号(主键)self.count=0#获取给定城市的七天天气,返回一个二维列表def getDataByCity(self,city):rows=[]myurl=self.url+self.citycode[city]+'.shtml'try:req=requests.get(myurl)req.raise_for_status()req.encoding=req.apparent_encodingexcept:print('error in request')returndata = req.textsoup=BeautifulSoup(data,'lxml')lis=soup.select("ul[class='t clearfix'] li")for li in lis:self.count+=1date=li.select('h1')[0].textinfo=li.select("p[class='wea']")[0].text# print(li)# print(len(li.select("p[class='tem'] span")))# print(len(li.select("p[class='tem'] i")))#由于可能没有span标签,所以最好判断一下,否则可能报错tmp=li.select("p[class='tem'] i")[0].textif len(li.select("p[class='tem'] span"))>0:tmp=li.select("p[class='tem'] span")[0].text+'/'+tmprows.append([self.count,city,date,info,tmp])return rows#把得到的数据存进weather.dbdef savedata(self,cities):db=DB()db.open()for city in cities:rows=self.getDataByCity(city)for row in rows:db.insert(row[0], row[1], row[2], row[3], row[4])db.show()db.close()#main创建weatherforest对象并且调用savedata
def main():cities=['北京','上海','广州','深圳']forest=weatherforest()forest.savedata(cities)if __name__=='__main__':main()
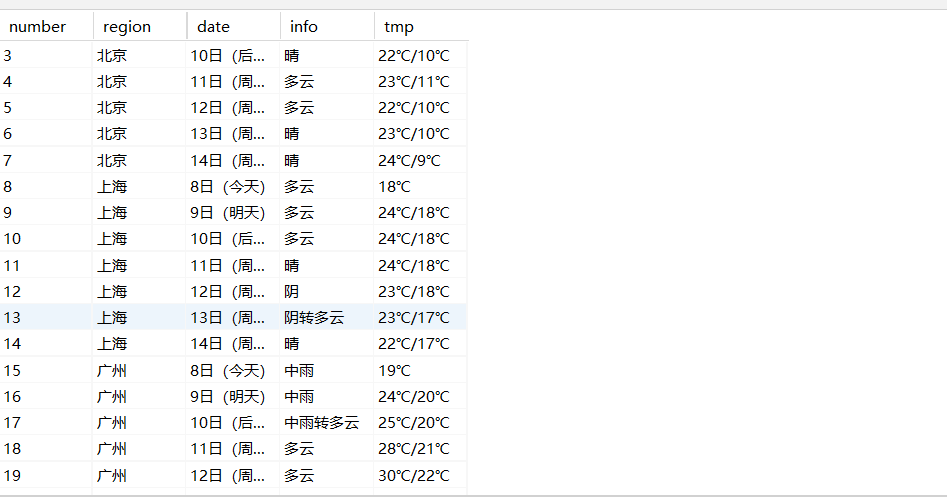
运行结果
2)心得体会
主要练习了sqlite库的基本使用,request爬取网页元素beautifulsoup解析,css标签选择
作业②:
1)
gitee链接:
https://gitee.com/zxbaixuexi/scrapy_homework/tree/master/作业2/2
要求::用 requests 和 BeautifulSoup 库方法定向爬取股票相关信息,并
存储在数据库中。
代码
import json
import requests
import re
import sqlite3
# import pandas as pd#创建DB对象操作sqlite
class DB:#创建空的stock.dbdef open(self):self.connection=sqlite3.Connection('stock.db')self.cursor=self.connection.cursor()try:self.cursor.execute('create table stock(序号 Integer primary key autoincrement,股票代码 vachar(16),股票名称 vachar(16),最新报价 real,涨跌幅 real,涨跌额 real,成交量 real,成交额 real,振幅 real,最高 real,最低 real,今开 real,昨收 real)')except:self.cursor.execute('delete from stock')#关闭stock.dbdef close(self):self.connection.commit()self.cursor.close()#插入数据到stock.dbdef insert(self,mylist):dm, mc, bj, zdf, zde, cjl, cje, zf, max, min, jk, zs=mylistself.cursor.execute('insert into stock(股票代码, 股票名称, 最新报价,涨跌幅, 涨跌额, 成交量, 成交额, 振幅, 最高, 最低, 今开, 昨收) values(?,?,?,?,?,?,?,?,?,?,?,?)',(dm,mc,bj,zdf,zde,cjl,cje,zf,max,min,jk,zs))# def show(self):# self.cursor.execute('select * from weather')# rows=self.cursor.fetchall()# print('序号','地区','日期','天气信息','温度',sep='\t')# for row in rows:# print(row[0],row[1],row[2],row[3],row[4],sep='\t')#用get方法访问服务器并提取页面全部数据,返回值为{'diff':[{},{},{},.....]}
def getHtml(page):myhead={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.43'}# url = "http://nufm.dfcfw.com/EM_Finance2014NumericApplication/JS.aspx?cb=jQuery112406115645482397511_1542356447436&type=CT&token=4f1862fc3b5e77c150a2b985b12db0fd&sty=FCOIATC&js=(%7Bdata%3A%5B(x)%5D%2CrecordsFiltered%3A(tot)%7D)&cmd="+cmd+"&st=(ChangePercent)&sr=-1&p="+str(page)+"&ps=20"url=r'http://33.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112407178172568697108_1601424130469&pn='+str(page)+'&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1601424130602'r = requests.get(url,headers=myhead)r.raise_for_status()r.encoding=r.apparent_encodingresult = r.text#真# 正则表达式得到{'diff':[{},{}]}的json格式数据result = '{' + re.findall('"diff":\[.*?]', result)[0] + '}'#将json变为dictresult = json.loads(result)return result#提取单个页面股票数据,返回一个二维列表记录对应的数据
def getOnePageStock(page):stocks = []mydict={'股票代码':'f12','股票名称':'f14','最新报价':'f2','涨跌幅':'f3','涨跌额':'f4','成交量':'f5','成交额':'f6','振幅':'f7','最高':'f15','最低':'f16','今开':'f17','昨收':'f18'}try:data = getHtml(page)except:print(page)dict_list = data['diff']#循环提取需要的数据for dict in dict_list:stock=[]for f in mydict.values():myvalue=dict[f]stock.append(myvalue)stocks.append(stock)return stocks#将getOnePageStock(1-pages_num)提取到的有用的数据存入stock.db
def getallsave():global pages_numdb=DB()db.open()for i in range(pages_num):datas=getOnePageStock(i+1)for data in datas:db.insert(data)db.close()def main():getallsave()if __name__=='__main__':#总计277,但是267-277爬不了pages_num=266main()
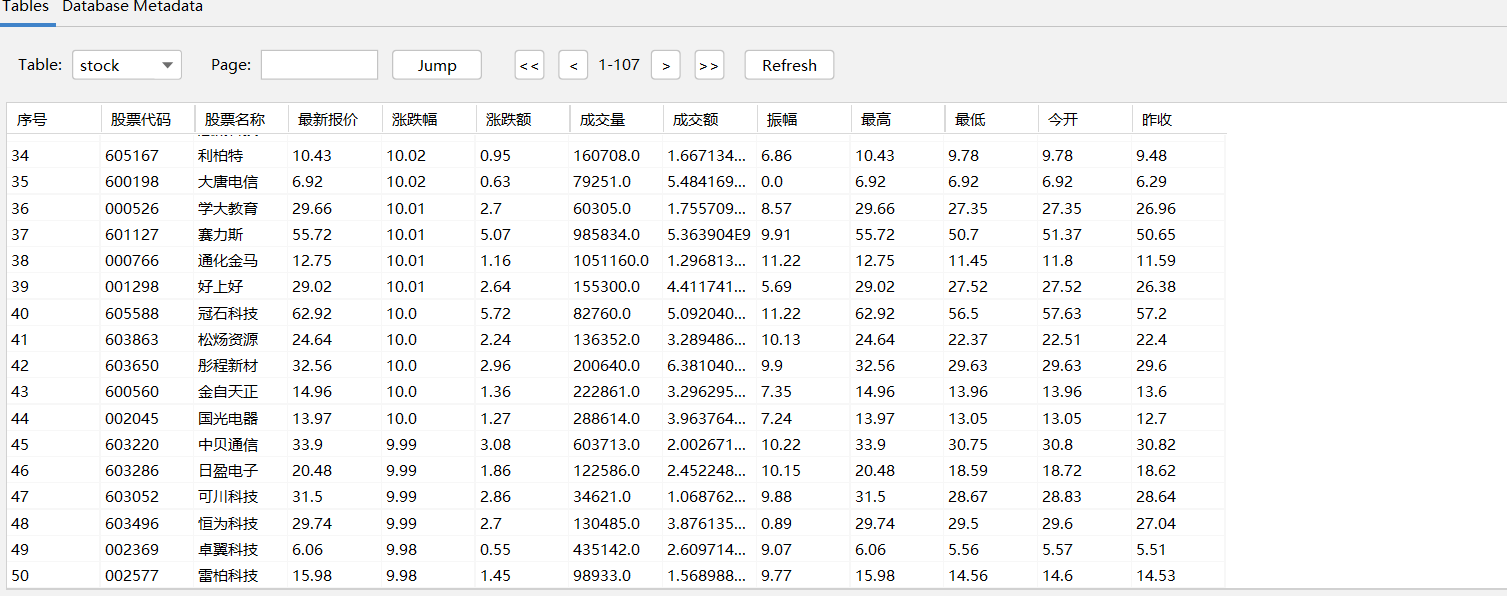
运行结果
2)心得体会
主要练习了通过抓包找api,通过更改请求的值来实现翻页抓取等,可以获取通过网页元素爬取难以获取的值
作业③:
1)
gitee链接:
https://gitee.com/zxbaixuexi/scrapy_homework/tree/master/作业2/3
要求:爬取中国大学 2021 主榜
(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信
息,并存储在数据库中,同时将浏览器 F12 调试分析的过程录制 Gif 加
入至博客中。
代码
#排名,学校univenameCn,省市provice,类型univCategory,总分score
import requests
import re
import sqlite3#创建DB类用以操作sqlite
class DB:#创建空的schoolrank.dbdef open(self):self.connection=sqlite3.Connection('schoolrank.db')self.cursor=self.connection.cursor()try:self.cursor.execute('create table schoolrank(排行 Integer primary key autoincrement,学校 vachar(16),省市 vachar(16),类型 vachar(16),总分 real)')except:self.cursor.execute('delete from schoolrank')#关闭schoolrank.dbdef close(self):self.connection.commit()self.cursor.close()#插入数据def insert(self,name,province,cata,score):self.cursor.execute('insert into schoolrank(学校,省市,类型,总分) values(?,?,?,?)',(name,province,cata,score))url=r'https://www.shanghairanking.cn/_nuxt/static/1696822285/rankings/bcur/2021/payload.js'
req=requests.get(url)
req.raise_for_status()
req.encoding=req.apparent_encoding
data=req.text#func_data_key为一个[key1,key2,...],key为str
func_data_key=data[len('__NUXT_JSONP__("/rankings/bcur/2021", (function('):data.find(')')].split(',')print(data)
#正则获取univerCn,province,univerCategory,score
univerCnlist=re.findall('univNameCn:"(.*?)",',data)
provincelist=re.findall('province:(.*?),',data)
univerCategorylist=re.findall('univCategory:(.*?),',data)
scorelist=re.findall('score:(.*?),',data)
print(univerCnlist)
print(len(univerCnlist))#获取func_data_value为[vlaue,value,....]
func_data_value=data[data.rfind('(')+1:-4].split(',')
#将二者配对
cnt=0
mydict={}
for key in func_data_key:value=func_data_value[cnt]mydict[key]=valuecnt+=1#提取其中有用的信息
name=univerCnlist
province=[]
for item in provincelist:province.append(mydict[item])
cate=[]
for item in univerCategorylist:cate.append(mydict[item])db=DB()
db.open()
for i in range(len(name)):db.insert(name[i],province[i],cate[i],scorelist[i])
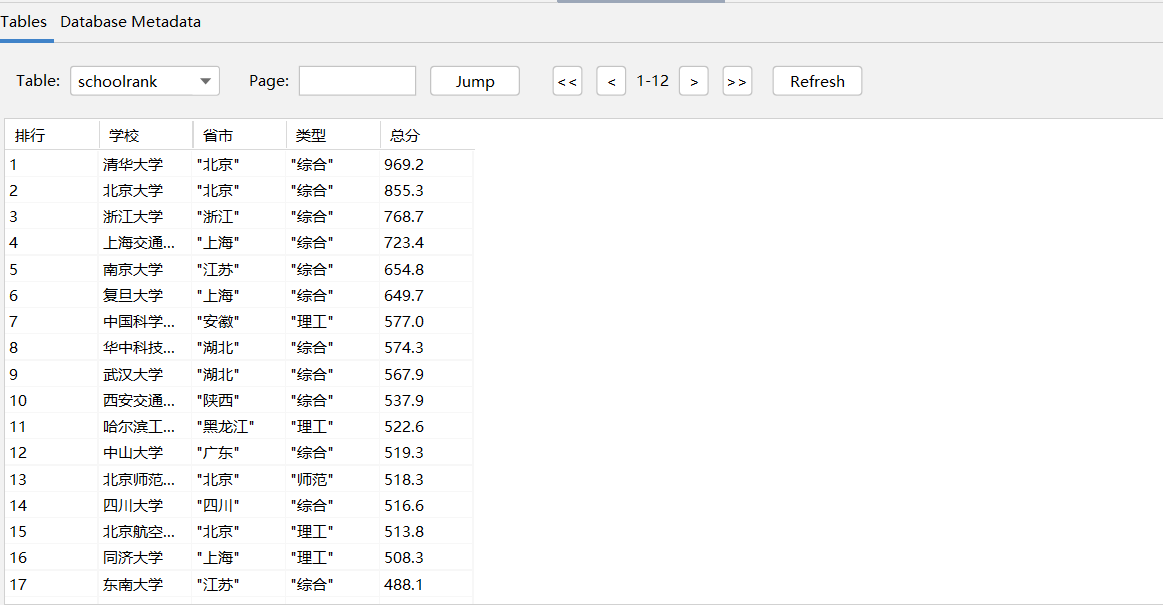
db.close()运行结果
2)心得体会
练习了api获取信息,另外就是正则表达式提取数据,另外还需要了解一些js的知识(这次key_value),通过搜索关键字来筛选想要的文件