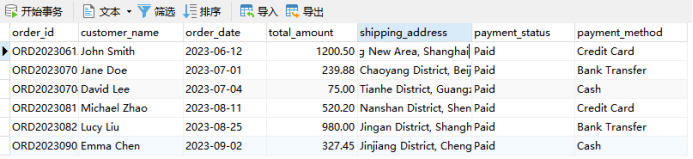
(之前写了一个flink-cdc同步数据的博客,发布在某N,最近代码开源了,直接复制过来了,懒得重新写了,将就着看下吧)
最近做的一个项目,使用的是pg数据库,公司没有成熟的DCD组件,为了实现数据变更消息发布的功能,我使用SpringBoot集成Flink-CDC 采集PostgreSQL变更数据发布到Kafka。
一、业务价值
监听数据变化,进行异步通知,做系统内异步任务。
架构方案(懒得写了,看图吧):

二、修改数据库配置
2.1、更改配置文件postgresql.conf
# 更改wal日志方式为logical(必须)wal_level = logical # minimal, replica, or logical# 更改solts最大数量(默认值为10),flink-cdc默认一张表占用一个slots(每个文档都这么说,但根据我的实际操作来看,一个flink-cdc服务占用一个槽,但是要大于默认值10)max_replication_slots = 20 # max number of replication slots# 更改wal发送最大进程数(默认值为10),这个值和上面的solts设置一样max_wal_senders = 20 # max number of walsender processes# 中断那些停止活动超过指定毫秒数的复制连接,可以适当设置大一点(默认60s)wal_sender_timeout = 180s # in milliseconds; 0 disable
2.2、创建数据变更采集用户及赋权
-- 创建pg 高线数据同步用户create user offline_data_user with password 'password';-- 给用户复制流权限alter role offline_data_user replication;-- 给用户登录pmsdb数据库权限grant connect on database 数据库名 to offline_data_user;-- 给用户授予数据库XXXX下某些SCHEMA的XXX表的读作权限grant select on all tables in SCHEMA 某 to offline_data_user;grant usage on SCHEMA 某 to offline_data_user;
2.3、发布表
-- 设置表发布为trueupdate pg publication set pubalitables=true where pubname is not null;-- 发表所有表create PUBLICATION dbz publication FOR ALL TABLES;
三、SpringBoot集成Flink-CDC
3.1、添加Flink-CDC的依赖
<properties><flink.version>1.16.0</flink.version><flink-pg.version>2.3.0</flink-pg.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency><dependency><groupId>com.ververica</groupId><artifactId>flink-connector-postgres-cdc</artifactId><version>${flink-pg.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency></dependencies>
3.2 构建数据源
数据转换类,将从数据库采集的转成你想要的格式:
{"beforeData": "","afterData": "","eventType": "","database": "","schema": "","tableName": "","changeTime": 0}
数据实体类 DataChangeInfo
package com.jie.flink.cdc.doman;import lombok.Data;import java.io.Serializable;/*** @author zhanggj* @data 2023/1/31*/@Datapublic class DataChangeInfo implements Serializable {/*** 变更前数据*/private String beforeData;/*** 变更后数据*/private String afterData;/*** 变更类型 create=新增、update=修改、delete=删除、read=初始读*/private String eventType;/*** 数据库名*/private String database;/*** schema*/private String schema;/*** 表名*/private String tableName;/*** 变更时间*/private Long changeTime;}
数据解析类PostgreSQLDeserialization
package com.jie.flink.cdc.flinksource;import com.esotericsoftware.minlog.Log;import com.jie.flink.cdc.datafilter.PostgreSQLDataFilter;import com.jie.flink.cdc.doman.DataChangeInfo;import com.jie.flink.cdc.util.JsonUtils;import com.ververica.cdc.debezium.DebeziumDeserializationSchema;import io.debezium.data.Envelope;import lombok.extern.slf4j.Slf4j;import org.apache.flink.api.common.typeinfo.TypeInformation;import org.apache.flink.util.Collector;import org.apache.kafka.connect.data.Field;import org.apache.kafka.connect.data.Schema;import org.apache.kafka.connect.data.Struct;import org.apache.kafka.connect.source.SourceRecord;import java.util.HashMap;import java.util.List;import java.util.Map;import java.util.Objects;import java.util.Optional;/*** @author zhanggj* @data 2023/1/31* 数据转换*/@Slf4jpublic class PostgreSQLDeserialization implements DebeziumDeserializationSchema<String> {public static final String TS_MS = "ts_ms";public static final String DATABASE = "db";public static final String SCHEMA = "schema";public static final String TABLE = "table";public static final String BEFORE = "before";public static final String AFTER = "after";public static final String SOURCE = "source";/**** 反序列化数据,转为变更JSON对象* @param sourceRecord* @param collector* @return void* @author lei* @date 2022-08-25 14:44:31*/@Overridepublic void deserialize(SourceRecord sourceRecord, Collector<String> collector) {final String topic = sourceRecord.topic();log.debug("收到{}的消息,准备进行转换", topic);final DataChangeInfo dataChangeInfo = new DataChangeInfo();final Struct struct = (Struct) sourceRecord.value();final Struct source = struct.getStruct(SOURCE);dataChangeInfo.setBeforeData( getDataJsonString(struct, BEFORE));dataChangeInfo.setAfterData(getDataJsonString(struct, AFTER));//5.获取操作类型 CREATE UPDATE DELETEEnvelope.Operation operation = Envelope.operationFor(sourceRecord);dataChangeInfo.setEventType(operation.toString().toLowerCase());dataChangeInfo.setDatabase(Optional.ofNullable(source.get(DATABASE)).map(Object::toString).orElse(""));dataChangeInfo.setSchema(Optional.ofNullable(source.get(SCHEMA)).map(Object::toString).orElse(""));dataChangeInfo.setTableName(Optional.ofNullable(source.get(TABLE)).map(Object::toString).orElse(""));dataChangeInfo.setChangeTime(Optional.ofNullable(struct.get(TS_MS)).map(x -> Long.parseLong(x.toString())).orElseGet(System::currentTimeMillis));log.info("收到{}的{}类型的消息, 已经转换好了,准备发往sink", topic, dataChangeInfo.getEventType());//7.输出数据collector.collect(JsonUtils.toJSONString(dataChangeInfo));}private String getDataJsonString(final Struct struct, final String fieldName) {if (Objects.isNull(struct)) {return null;}final Struct element = struct.getStruct(fieldName);if (Objects.isNull(element)) {return null;}Map<String, Object> dataMap = new HashMap<>();Schema schema = element.schema();List<Field> fieldList = schema.fields();for (Field field : fieldList) {dataMap.put(field.name(), element.get(field));}return JsonUtils.toJSONString(dataMap);}@Overridepublic TypeInformation<String> getProducedType() {return TypeInformation.of(String.class);}}
构建PG数据源PostgreSQLDataChangeSource
package com.jie.flink.cdc.flinksource;import com.jie.flink.cdc.datafilter.PostgreSQLReadDataFilter;import com.ververica.cdc.connectors.postgres.PostgreSQLSource;import com.ververica.cdc.debezium.DebeziumSourceFunction;import lombok.Data;import org.apache.commons.lang3.StringUtils;import org.springframework.beans.factory.annotation.Value;import org.springframework.context.annotation.Bean;import org.springframework.stereotype.Component;import java.util.Properties;import java.util.UUID;/*** @author zhanggj* @data 2023/2/10* flink pg 数据源配置*/@Data@Componentpublic class PostgreSQLDataChangeSource {/*** 数据库hostname*/private String hostName;/*** 数据库 端口*/private Integer port;/*** 库名*/private String database;/*** 用户名*/@Value("${spring.datasource.username}")private String userName;/*** 密码*/@Value("${spring.datasource.password}")private String password;/*** schema 组*/@Value("${jie.flink-cdc.stream.source.schemas:test_schema}")private String[] schemaArray;/*** 要监听的表*/@Value("${jie.flink-cdc.stream.source.schemas:test_table}")private String[] tableArray;/*** 是否忽略初始化扫描数据*/@Value("${jie.flink-cdc.stream.source.init-read.ignore:false}")private Boolean initReadIgnore;@Value("${spring.datasource.url}")private void splitUrl(String url) {final String[] urlSplit = StringUtils.split(url, "/");final String[] hostPortSplit = StringUtils.split(urlSplit[1], ":");this.hostName = hostPortSplit[0];this.port = Integer.parseInt(hostPortSplit[1]);this.database = StringUtils.substringBefore(urlSplit[2], "?");}@Bean("pgDataSource")public DebeziumSourceFunction<String> buildPostgreSQLDataSource() {Properties properties = new Properties();// 指定连接器启动时执行快照的条件:****重要*****//initial- 连接器仅在没有为逻辑服务器名称记录偏移量时才执行快照。//always- 连接器每次启动时都会执行快照。//never- 连接器从不执行快照。//initial_only- 连接器执行初始快照然后停止,不处理任何后续更改。//exported- 连接器根据创建复制槽的时间点执行快照。这是一种以无锁方式执行快照的绝佳方式。//custom- 连接器根据snapshot.custom.class属性的设置执行快照properties.setProperty("debezium.snapshot.mode", "initial");properties.setProperty("snapshot.mode", "initial");// 好像不起作用使用slot.nameproperties.setProperty("debezium.slot.name", "pg_cdc" + UUID.randomUUID());properties.setProperty("slot.name", "flink_slot" + UUID.randomUUID());properties.setProperty("debezium.slot.drop.on.top", "true");properties.setProperty("slot.drop.on.top", "true");// 更多参数配置参考debezium官网 https://debezium.io/documentation/reference/1.2/connectors/postgresql.html?spm=a2c4g.11186623.0.0.4d485fb3rgWieD#postgresql-property-snapshot-mode// 或阿里文档 https://help.aliyun.com/document_detail/184861.htmlPostgreSQLDeserialization deserialization = null;if (initReadIgnore) {properties.setProperty("debezium.snapshot.mode", "never");properties.setProperty("snapshot.mode", "never");deserialization = new PostgreSQLDeserialization(new PostgreSQLReadDataFilter());} else {deserialization = new PostgreSQLDeserialization();}return PostgreSQLSource.<String>builder().hostname(hostName).port(port).username(userName).password(password).database(database).schemaList(schemaArray).tableList(tableArray).decodingPluginName("pgoutput").deserializer(deserialization).debeziumProperties(properties).build();}}
改正:数据源配置的slot.name不能配置随机的id,需要固定,因为这个涉及到wal日志采集,一个槽记录了一种客户端的采集信息(里面会有当前客户端的checkpoint)。因此对于一个数据源来说这个slot.name应该是固定的。至于高可用,只有主备这种方案……
3.3、构建kafkaSink
package com.jie.flink.cdc.flinksink;import lombok.Data;import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.connector.base.DeliveryGuarantee;import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;import org.apache.flink.connector.kafka.sink.KafkaSink;import org.springframework.beans.factory.annotation.Value;import org.springframework.context.annotation.Bean;import org.springframework.stereotype.Component;/*** @author zhanggj* @data 2023/2/10* flink kafka sink配置*/@Data@Componentpublic class FlinkKafkaSink {@Value("${jie.flink-cdc.stream.sink.topic:offline_data_topic}")private String topic;@Value("${spring.kafka.bootstrap-servers}")private String kafkaBootstrapServers;@Bean("kafkaSink")public KafkaSink buildFlinkKafkaSink() {return KafkaSink.<String>builder().setBootstrapServers(kafkaBootstrapServers).setRecordSerializer(KafkaRecordSerializationSchema.builder().setTopic(topic).setValueSerializationSchema(new SimpleStringSchema()).build()).setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE).build();}}
3.4、创建flink-cdc监听
利用springboot的特性, 实现CommandLineRunner将flink-cdc 作为一个项目启动时需要运行的分支子任务即可
package com.jie.flink.cdc.listener;import com.jie.flink.cdc.flinksink.DataChangeSink;import com.ververica.cdc.debezium.DebeziumSourceFunction;import org.apache.flink.api.common.restartstrategy.RestartStrategies;import org.apache.flink.connector.kafka.sink.KafkaSink;import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;import org.apache.flink.streaming.api.CheckpointingMode;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.CheckpointConfig;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.springframework.boot.CommandLineRunner;import org.springframework.stereotype.Component;import java.time.Duration;/*** @author zhanggj* @data 2023/1/31* 监听数据变更*/@Componentpublic class PostgreSQLEventListener implements CommandLineRunner {private final DataChangeSink dataChangeSink;private final KafkaSink<String> kafkaSink;private final DebeziumSourceFunction<String> pgDataSource;public PostgreSQLEventListener(final DataChangeSink dataChangeSink,final KafkaSink<String> kafkaSink,final DebeziumSourceFunction<String> pgDataSource) {this.dataChangeSink = dataChangeSink;this.kafkaSink = kafkaSink;this.pgDataSource = pgDataSource;}@Overridepublic void run(final String... args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.disableOperatorChaining();env.enableCheckpointing(6000L);// 配置checkpoint 超时时间env.getCheckpointConfig().setCheckpointTimeout(Duration.ofMinutes(60).toMillis());//指定 CK 的一致性语义env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);//设置任务关闭的时候保留最后一次 CK 数据env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);// 避免扫描快照超时env.getCheckpointConfig().setTolerableCheckpointFailureNumber(100);env.getCheckpointConfig().setCheckpointInterval(Duration.ofMinutes(10).toMillis());// 指定从 CK 自动重启策略env.setRestartStrategy(RestartStrategies.fixedDelayRestart(Integer.MAX_VALUE, 2000L));//设置状态后端env.setStateBackend(new HashMapStateBackend());DataStreamSource<String> pgDataStream = env.addSource(pgDataSource, "PostgreSQL-source").setParallelism(1);// sink到kafkapgDataStream.sinkTo(kafkaSink).name("sink2Kafka");env.execute("pg_cdc-kafka");}}
四、遇到的问题与解决
1、pg配置没有修改,DBA说一般情况下都有改过wal_level,呵呵,一定要确认wal_level = logical是必须的。
2、Creation of replication slot failed …… FATAL:number of requested standby connections exceeds max_wal_senders (currently 10)
求DBA大佬吧,需要改
3、Failed to start replication stream at LSN{0/1100AA50}; when setting up multiple connectors for the same database host, please make sure to use a distinct replication slot name for each.
很多文档理提供的创建数据源的代码里都只是指定了一个固定的slot.name 当你启动多个SpringBoot服务时,会报这个错误,我这个代码里直接用了UUID,其他能区分不同服务的也可以的。
properties.setProperty("debezium.slot.name", "pg_cdc" + UUID.randomUUID());
properties.setProperty("slot.name", "flink_slot" + UUID.randomUUID());
4、服务启动后一直在扫描快照数据,看日志,报了超时异常(异常找不到了,有空了造个再发出来)。
原因:(官网)During scanning snapshot of database tables, since there is no recoverable position, we can’t perform checkpoints. In order to not perform checkpoints, Postgres CDC source will keep the checkpoint waiting to timeout. The timeout checkpoint will be recognized as failed checkpoint, by default, this will trigger a failover for the Flink job. So if the database table is large, it is recommended to add following Flink configurations to avoid failover because of the timeout checkpoints:【Postgres CDC暂不支持在全表扫描阶段执行Checkpoint。如果您的作业在全表扫描阶段触发Checkpoint,则可能由于Checkpoint超时导致作业Failover。因此,建议您在作业开发页面高级配置的更多Flink配置中配置如下参数,避免在全量同步阶段由于Checkpoint超时导致Failover。】
execution.checkpointing.interval: 10min
execution.checkpointing.tolerable-failed-checkpoints: 100
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 2147483647
代码:
// 避免扫描快照超时env.getCheckpointConfig().setTolerableCheckpointFailureNumber(100);env.getCheckpointConfig().setCheckpointInterval(Duration.ofMinutes(10).toMillis());// 指定从 CK 自动重启策略env.setRestartStrategy(RestartStrategies.fixedDelayRestart(Integer.MAX_VALUE, 2000L));或者改超时时间配置// 配置checkpoint 超时时间env.getCheckpointConfig().setCheckpointTimeout(Duration.ofMinutes(600).toMillis());
没错,上面的时600分钟,其实对于我们的数据量(8千多万)60分钟这个配置还是不够的(单机),因此用了600分钟,但是,真正运行后报了另外的问题 OOM:Java heap space……
最后,直接关掉了快照数据的扫描
properties.setProperty("debezium.snapshot.mode", "never");
properties.setProperty("snapshot.mode", "never");
五、参考文档
Postgres的CDC源表
Debezium官网参数说明
flink cdc 整理
六、代码
源代码已经开源,需要的自取
flink-cdc组件源码
有问题可以加我wei信咨询 jiewolf
最近做的一个项目,使用的是pg数据库,公司没有成熟的DCD组件,为了实现数据变更消息发布的功能,我使用SpringBoot集成Flink-CDC 采集PostgreSQL变更数据发布到Kafka。一、业务价值监听数据变化,进行异步通知,做系统内异步任务。
架构方案(懒得写了,看图吧):
二、修改数据库配置2.1、更改配置文件postgresql.conf# 更改wal日志方式为logical(必须)wal_level = logical # minimal, replica, or logical
# 更改solts最大数量(默认值为10),flink-cdc默认一张表占用一个slots(每个文档都这么说,但根据我的实际操作来看,一个flink-cdc服务占用一个槽,但是要大于默认值10)max_replication_slots = 20 # max number of replication slots
# 更改wal发送最大进程数(默认值为10),这个值和上面的solts设置一样max_wal_senders = 20 # max number of walsender processes# 中断那些停止活动超过指定毫秒数的复制连接,可以适当设置大一点(默认60s)wal_sender_timeout = 180s # in milliseconds; 0 disable 2.2、创建数据变更采集用户及赋权-- 创建pg 高线数据同步用户create user offline_data_user with password 'password';
-- 给用户复制流权限alter role offline_data_user replication;
-- 给用户登录pmsdb数据库权限grant connect on database 数据库名 to offline_data_user;
-- 给用户授予数据库XXXX下某些SCHEMA的XXX表的读作权限grant select on all tables in SCHEMA 某 to offline_data_user;
grant usage on SCHEMA 某 to offline_data_user;
2.3、发布表
-- 设置表发布为trueupdate pg publication set pubalitables=true where pubname is not null;
-- 发表所有表create PUBLICATION dbz publication FOR ALL TABLES;
三、SpringBoot集成Flink-CDC3.1、添加Flink-CDC的依赖<properties>
<flink.version>1.16.0</flink.version> <flink-pg.version>2.3.0</flink-pg.version></properties><dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>com.ververica</groupId> <artifactId>flink-connector-postgres-cdc</artifactId> <version>${flink-pg.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka</artifactId> <version>${flink.version}</version> </dependency></dependencies>3.2 构建数据源数据转换类,将从数据库采集的转成你想要的格式:
{ "beforeData": "", "afterData": "", "eventType": "", "database": "", "schema": "", "tableName": "", "changeTime": 0}
数据实体类 DataChangeInfo
package com.jie.flink.cdc.doman; import lombok.Data; import java.io.Serializable; /** * @author zhanggj * @data 2023/1/31 */@Datapublic class DataChangeInfo implements Serializable { /** * 变更前数据 */ private String beforeData; /** * 变更后数据 */ private String afterData; /** * 变更类型 create=新增、update=修改、delete=删除、read=初始读 */ private String eventType; /** * 数据库名 */ private String database; /** * schema */ private String schema; /** * 表名 */ private String tableName; /** * 变更时间 */ private Long changeTime;}
数据解析类PostgreSQLDeserialization
package com.jie.flink.cdc.flinksource; import com.esotericsoftware.minlog.Log;import com.jie.flink.cdc.datafilter.PostgreSQLDataFilter;import com.jie.flink.cdc.doman.DataChangeInfo;import com.jie.flink.cdc.util.JsonUtils;import com.ververica.cdc.debezium.DebeziumDeserializationSchema;import io.debezium.data.Envelope;import lombok.extern.slf4j.Slf4j;import org.apache.flink.api.common.typeinfo.TypeInformation;import org.apache.flink.util.Collector;import org.apache.kafka.connect.data.Field;import org.apache.kafka.connect.data.Schema;import org.apache.kafka.connect.data.Struct;import org.apache.kafka.connect.source.SourceRecord; import java.util.HashMap;import java.util.List;import java.util.Map;import java.util.Objects;import java.util.Optional; /** * @author zhanggj * @data 2023/1/31 * 数据转换 */@Slf4jpublic class PostgreSQLDeserialization implements DebeziumDeserializationSchema<String> { public static final String TS_MS = "ts_ms"; public static final String DATABASE = "db"; public static final String SCHEMA = "schema"; public static final String TABLE = "table"; public static final String BEFORE = "before"; public static final String AFTER = "after"; public static final String SOURCE = "source"; /** * * 反序列化数据,转为变更JSON对象 * @param sourceRecord * @param collector * @return void * @author lei * @date 2022-08-25 14:44:31 */ @Override public void deserialize(SourceRecord sourceRecord, Collector<String> collector) { final String topic = sourceRecord.topic(); log.debug("收到{}的消息,准备进行转换", topic); final DataChangeInfo dataChangeInfo = new DataChangeInfo(); final Struct struct = (Struct) sourceRecord.value(); final Struct source = struct.getStruct(SOURCE); dataChangeInfo.setBeforeData( getDataJsonString(struct, BEFORE)); dataChangeInfo.setAfterData(getDataJsonString(struct, AFTER)); //5.获取操作类型 CREATE UPDATE DELETE Envelope.Operation operation = Envelope.operationFor(sourceRecord); dataChangeInfo.setEventType(operation.toString().toLowerCase()); dataChangeInfo.setDatabase(Optional.ofNullable(source.get(DATABASE)).map(Object::toString).orElse("")); dataChangeInfo.setSchema(Optional.ofNullable(source.get(SCHEMA)).map(Object::toString).orElse("")); dataChangeInfo.setTableName(Optional.ofNullable(source.get(TABLE)).map(Object::toString).orElse("")); dataChangeInfo.setChangeTime(Optional.ofNullable(struct.get(TS_MS)).map(x -> Long.parseLong(x.toString())).orElseGet(System::currentTimeMillis)); log.info("收到{}的{}类型的消息, 已经转换好了,准备发往sink", topic, dataChangeInfo.getEventType()); //7.输出数据 collector.collect(JsonUtils.toJSONString(dataChangeInfo)); } private String getDataJsonString(final Struct struct, final String fieldName) { if (Objects.isNull(struct)) { return null; } final Struct element = struct.getStruct(fieldName); if (Objects.isNull(element)) { return null; } Map<String, Object> dataMap = new HashMap<>(); Schema schema = element.schema(); List<Field> fieldList = schema.fields(); for (Field field : fieldList) { dataMap.put(field.name(), element.get(field)); } return JsonUtils.toJSONString(dataMap); } @Override public TypeInformation<String> getProducedType() { return TypeInformation.of(String.class); }}
构建PG数据源PostgreSQLDataChangeSource
package com.jie.flink.cdc.flinksource; import com.jie.flink.cdc.datafilter.PostgreSQLReadDataFilter;import com.ververica.cdc.connectors.postgres.PostgreSQLSource;import com.ververica.cdc.debezium.DebeziumSourceFunction;import lombok.Data;import org.apache.commons.lang3.StringUtils;import org.springframework.beans.factory.annotation.Value;import org.springframework.context.annotation.Bean;import org.springframework.stereotype.Component; import java.util.Properties;import java.util.UUID; /** * @author zhanggj * @data 2023/2/10 * flink pg 数据源配置 */@Data@Componentpublic class PostgreSQLDataChangeSource { /** * 数据库hostname */ private String hostName; /** * 数据库 端口 */ private Integer port; /** * 库名 */ private String database; /** * 用户名 */ @Value("${spring.datasource.username}") private String userName; /** * 密码 */ @Value("${spring.datasource.password}") private String password; /** * schema 组 */ @Value("${jie.flink-cdc.stream.source.schemas:test_schema}") private String[] schemaArray; /** * 要监听的表 */ @Value("${jie.flink-cdc.stream.source.schemas:test_table}") private String[] tableArray; /** * 是否忽略初始化扫描数据 */ @Value("${jie.flink-cdc.stream.source.init-read.ignore:false}") private Boolean initReadIgnore; @Value("${spring.datasource.url}") private void splitUrl(String url) { final String[] urlSplit = StringUtils.split(url, "/"); final String[] hostPortSplit = StringUtils.split(urlSplit[1], ":"); this.hostName = hostPortSplit[0]; this.port = Integer.parseInt(hostPortSplit[1]); this.database = StringUtils.substringBefore(urlSplit[2], "?"); } @Bean("pgDataSource") public DebeziumSourceFunction<String> buildPostgreSQLDataSource() { Properties properties = new Properties(); // 指定连接器启动时执行快照的条件:****重要***** //initial- 连接器仅在没有为逻辑服务器名称记录偏移量时才执行快照。 //always- 连接器每次启动时都会执行快照。 //never- 连接器从不执行快照。 //initial_only- 连接器执行初始快照然后停止,不处理任何后续更改。 //exported- 连接器根据创建复制槽的时间点执行快照。这是一种以无锁方式执行快照的绝佳方式。 //custom- 连接器根据snapshot.custom.class属性的设置执行快照 properties.setProperty("debezium.snapshot.mode", "initial"); properties.setProperty("snapshot.mode", "initial"); // 好像不起作用使用slot.name properties.setProperty("debezium.slot.name", "pg_cdc" + UUID.randomUUID()); properties.setProperty("slot.name", "flink_slot" + UUID.randomUUID()); properties.setProperty("debezium.slot.drop.on.top", "true"); properties.setProperty("slot.drop.on.top", "true"); // 更多参数配置参考debezium官网 https://debezium.io/documentation/reference/1.2/connectors/postgresql.html?spm=a2c4g.11186623.0.0.4d485fb3rgWieD#postgresql-property-snapshot-mode // 或阿里文档 https://help.aliyun.com/document_detail/184861.html PostgreSQLDeserialization deserialization = null; if (initReadIgnore) { properties.setProperty("debezium.snapshot.mode", "never"); properties.setProperty("snapshot.mode", "never"); deserialization = new PostgreSQLDeserialization(new PostgreSQLReadDataFilter()); } else { deserialization = new PostgreSQLDeserialization(); } return PostgreSQLSource.<String>builder() .hostname(hostName) .port(port) .username(userName) .password(password) .database(database) .schemaList(schemaArray) .tableList(tableArray) .decodingPluginName("pgoutput") .deserializer(deserialization) .debeziumProperties(properties) .build(); }}
改正:数据源配置的slot.name不能配置随机的id,需要固定,因为这个涉及到wal日志采集,一个槽记录了一种客户端的采集信息(里面会有当前客户端的checkpoint)。因此对于一个数据源来说这个slot.name应该是固定的。至于高可用,只有主备这种方案……
3.3、构建kafkaSinkpackage com.jie.flink.cdc.flinksink; import lombok.Data;import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.connector.base.DeliveryGuarantee;import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;import org.apache.flink.connector.kafka.sink.KafkaSink;import org.springframework.beans.factory.annotation.Value;import org.springframework.context.annotation.Bean;import org.springframework.stereotype.Component; /** * @author zhanggj * @data 2023/2/10 * flink kafka sink配置 */@Data@Componentpublic class FlinkKafkaSink { @Value("${jie.flink-cdc.stream.sink.topic:offline_data_topic}") private String topic; @Value("${spring.kafka.bootstrap-servers}") private String kafkaBootstrapServers; @Bean("kafkaSink") public KafkaSink buildFlinkKafkaSink() { return KafkaSink.<String>builder() .setBootstrapServers(kafkaBootstrapServers) .setRecordSerializer(KafkaRecordSerializationSchema.builder() .setTopic(topic) .setValueSerializationSchema(new SimpleStringSchema()) .build()) .setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE) .build(); }}
3.4、创建flink-cdc监听利用springboot的特性, 实现CommandLineRunner将flink-cdc 作为一个项目启动时需要运行的分支子任务即可
package com.jie.flink.cdc.listener; import com.jie.flink.cdc.flinksink.DataChangeSink;import com.ververica.cdc.debezium.DebeziumSourceFunction;import org.apache.flink.api.common.restartstrategy.RestartStrategies;import org.apache.flink.connector.kafka.sink.KafkaSink;import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;import org.apache.flink.streaming.api.CheckpointingMode;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.CheckpointConfig;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.springframework.boot.CommandLineRunner;import org.springframework.stereotype.Component; import java.time.Duration; /** * @author zhanggj * @data 2023/1/31 * 监听数据变更 */@Componentpublic class PostgreSQLEventListener implements CommandLineRunner { private final DataChangeSink dataChangeSink; private final KafkaSink<String> kafkaSink; private final DebeziumSourceFunction<String> pgDataSource; public PostgreSQLEventListener(final DataChangeSink dataChangeSink, final KafkaSink<String> kafkaSink, final DebeziumSourceFunction<String> pgDataSource) { this.dataChangeSink = dataChangeSink; this.kafkaSink = kafkaSink; this.pgDataSource = pgDataSource; } @Override public void run(final String... args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); env.disableOperatorChaining(); env.enableCheckpointing(6000L); // 配置checkpoint 超时时间 env.getCheckpointConfig().setCheckpointTimeout(Duration.ofMinutes(60).toMillis()); //指定 CK 的一致性语义 env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); //设置任务关闭的时候保留最后一次 CK 数据 env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); // 避免扫描快照超时 env.getCheckpointConfig().setTolerableCheckpointFailureNumber(100); env.getCheckpointConfig().setCheckpointInterval(Duration.ofMinutes(10).toMillis()); // 指定从 CK 自动重启策略 env.setRestartStrategy(RestartStrategies.fixedDelayRestart(Integer.MAX_VALUE, 2000L)); //设置状态后端 env.setStateBackend(new HashMapStateBackend()); DataStreamSource<String> pgDataStream = env.addSource(pgDataSource, "PostgreSQL-source") .setParallelism(1); // sink到kafka pgDataStream.sinkTo(kafkaSink).name("sink2Kafka"); env.execute("pg_cdc-kafka"); } }
四、遇到的问题与解决1、pg配置没有修改,DBA说一般情况下都有改过wal_level,呵呵,一定要确认wal_level = logical是必须的。
2、Creation of replication slot failed …… FATAL:number of requested standby connections exceeds max_wal_senders (currently 10)
求DBA大佬吧,需要改
3、Failed to start replication stream at LSN{0/1100AA50}; when setting up multiple connectors for the same database host, please make sure to use a distinct replication slot name for each.
很多文档理提供的创建数据源的代码里都只是指定了一个固定的slot.name 当你启动多个SpringBoot服务时,会报这个错误,我这个代码里直接用了UUID,其他能区分不同服务的也可以的。
properties.setProperty("debezium.slot.name", "pg_cdc" + UUID.randomUUID()); properties.setProperty("slot.name", "flink_slot" + UUID.randomUUID());4、服务启动后一直在扫描快照数据,看日志,报了超时异常(异常找不到了,有空了造个再发出来)。
原因:(官网)During scanning snapshot of database tables, since there is no recoverable position, we can’t perform checkpoints. In order to not perform checkpoints, Postgres CDC source will keep the checkpoint waiting to timeout. The timeout checkpoint will be recognized as failed checkpoint, by default, this will trigger a failover for the Flink job. So if the database table is large, it is recommended to add following Flink configurations to avoid failover because of the timeout checkpoints:【Postgres CDC暂不支持在全表扫描阶段执行Checkpoint。如果您的作业在全表扫描阶段触发Checkpoint,则可能由于Checkpoint超时导致作业Failover。因此,建议您在作业开发页面高级配置的更多Flink配置中配置如下参数,避免在全量同步阶段由于Checkpoint超时导致Failover。】
execution.checkpointing.interval: 10minexecution.checkpointing.tolerable-failed-checkpoints: 100restart-strategy: fixed-delayrestart-strategy.fixed-delay.attempts: 2147483647代码:
// 避免扫描快照超时 env.getCheckpointConfig().setTolerableCheckpointFailureNumber(100); env.getCheckpointConfig().setCheckpointInterval(Duration.ofMinutes(10).toMillis()); // 指定从 CK 自动重启策略 env.setRestartStrategy(RestartStrategies.fixedDelayRestart(Integer.MAX_VALUE, 2000L));或者改超时时间配置
// 配置checkpoint 超时时间 env.getCheckpointConfig().setCheckpointTimeout(Duration.ofMinutes(600).toMillis());没错,上面的时600分钟,其实对于我们的数据量(8千多万)60分钟这个配置还是不够的(单机),因此用了600分钟,但是,真正运行后报了另外的问题 OOM:Java heap space……
最后,直接关掉了快照数据的扫描
properties.setProperty("debezium.snapshot.mode", "never"); properties.setProperty("snapshot.mode", "never");五、参考文档Postgres的CDC源表
Debezium官网参数说明
flink cdc 整理
六、代码源代码已经开源,需要的自取
flink-cdc组件源码
有问题可以加我wei信咨询 jiewolf————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。 原文链接:https://blog.csdn.net/jiewolf/article/details/128972602




.assets/20240204225551.png)
![RaspberryPi笔记[4]-使用esp01s模块获取NTP时间](https://img2024.cnblogs.com/blog/1048201/202402/1048201-20240206004954479-102417543.png)