该文档是一些配置全分布的注意事项(遇到的坑)与个人的一些指令备注,阅读文档前需要配置好网络,具体可以参考:
网络配置。
linux系统选择的是Centos7
首先是一些小工具:
小技巧
1.Xshell:可以更方便地批量操控虚拟机进行全分布:
这样输入任何指令都可以输入给所有虚拟机,方便全分布的配置。
2.共享文件夹:前提是需要安装VMware Tools,(如图在设置的上面)
共享文件夹可以很方便的在Windows指定一个文件夹挂载到虚拟机上的/mnt/win(没有可以新建一个)文件夹下,
这样在Windows下把想发给虚拟机的文件放到指定的文件夹再输入指令:
/usr/bin/vmhgfs-fuse .host:/ /mnt/win -o subtype=vmhgfs-fuse,allow_other。
注:每次重新打开虚拟机之后都需要输入指令才能开启共享文件夹。
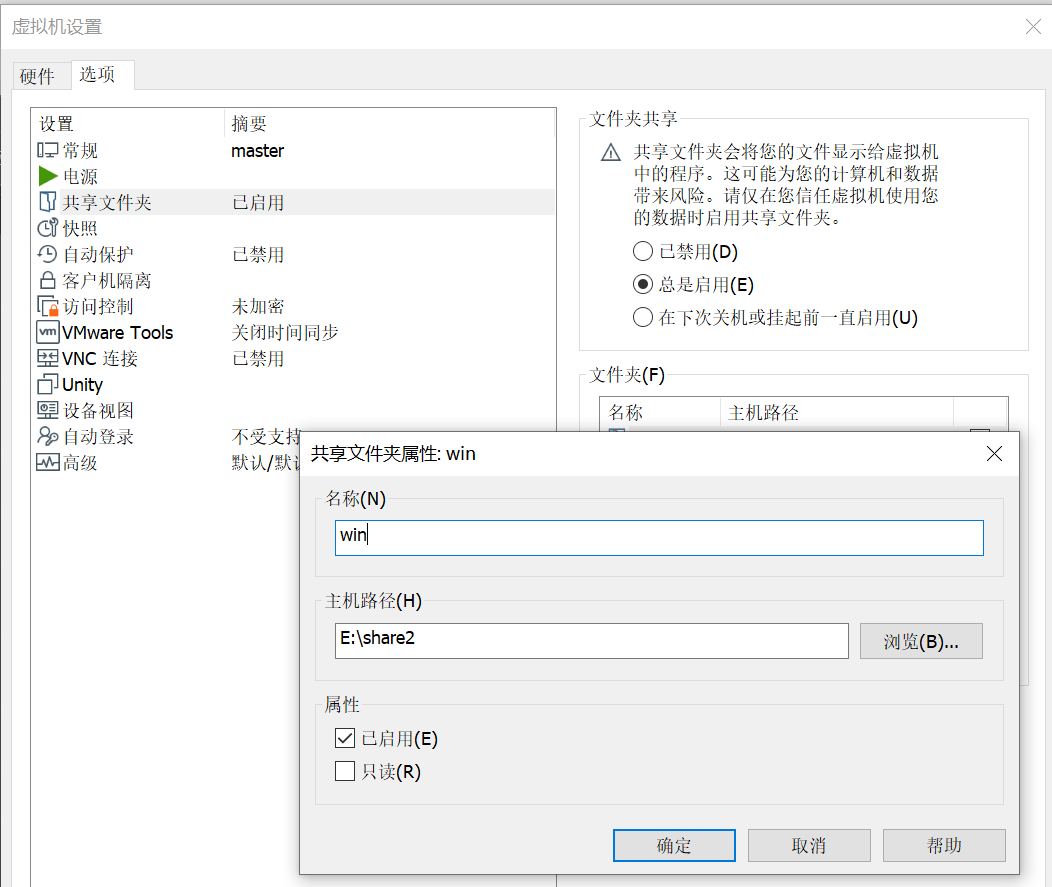
我这里选择的是E盘的share2(自建的)文件夹,你可以任意自己选择,上面的名称随意。
参考文章:Centos下虚拟机和物理机如何开启共享文件夹
注:你当然可以使用其他方法比如winscp工具等等……
一些常用指令
查看网络配置文件指令:
vim /etc/sysconfig/network-scripts/ifcfg-ens33
重启网络服务指令:
systemctl restart network
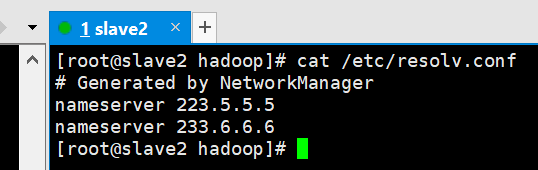
ping baidu.com不行,但是可以ping IP(如192.168.xxx.xxx),则需要修改DNS文件,修改完不要忘记重启网络服务:
vim /etc/resolv.conf
我这里添加的是如图:
全分布必备技能:克隆虚拟机
克隆前请注意关闭虚拟机!!!
此处参考了:克隆虚拟机注意事项,如本文不清楚可以见链接。
-
右键点击管理 --> 克隆 --> 创建完整克隆 -->名称、位置按个人来定
-
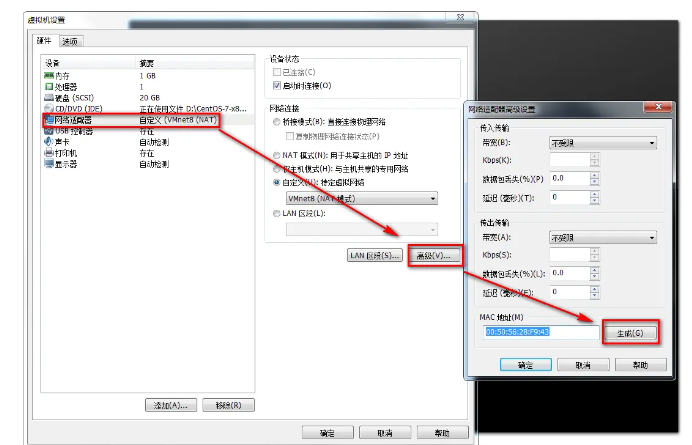
修改 MAC 地址,一般克隆完成后,虚拟机的网卡 MAC 地址会自动改变的,如果没有自动改变,可以手动修改。点击虚拟机设置,如图
-
修改 UUID,UUID 克隆虚拟机后一般是一样的,需要进行修改。
输入命令 uuidgen,将生成的 UUID 写入 ifcfg-ens33。vi /etc/sysconfig/network-scripts/ifcfg-ens33

-
修改 ip 地址(以你的为准)一般如果复制的是192.168.36.130,那么可以将克隆后的ip设置为192.168.36.131即可。
原理:如图编辑 -->虚拟机网络 --> 点击vmnet8,DHCP设置,如图,只要是起始结束之间的IP均可。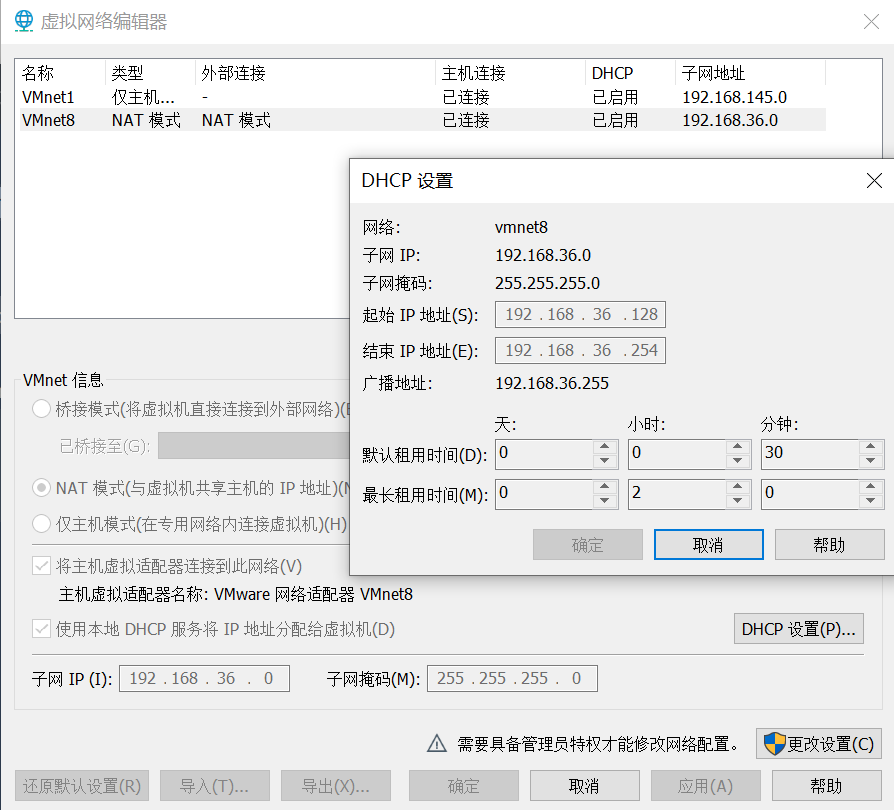
-
修改主机名,修改文件
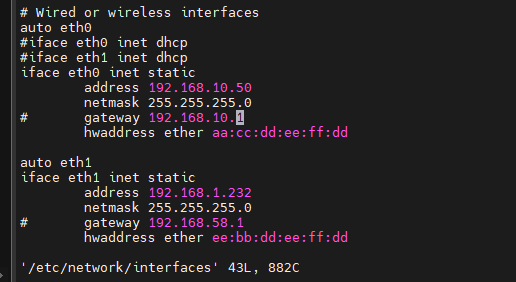
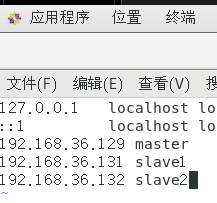
/etc/hosts和/etc/sysconfig/network,如下图所示:/etc/hosts(注:我这里是全分布)
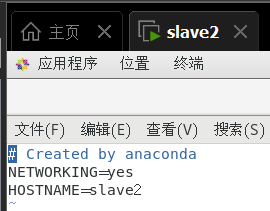
/etc/sysconfig/network
-
重启网络,
service network restart
ping baidu.com(大功告成!!!)
Spark全分布模式的安装和配置
Spark的安装模式一般分为三种:
1.伪分布模式:即在一个节点上模拟一个分布式环境,master和worker共用一个节点,这种模式一般用于开发和测试Spark程序;
2.全分布模式:即真正的集群模式,master和worker部署在不同的节点之上,一般至少需要3个节点(1个master和2个worker),这种模式一般用于实际的生产环境;
3.HA集群模式:即高可用集群模式,一般至少需要4台机器(1个主master,1个备master,2个worker),这种模式的优点是在主master宕机之后,备master会立即启动担任master的职责,可以保证集群高效稳定的运行,这种模式就是实际生产环境中多采用的模式。
本小节来介绍Spark的全分布模式的安装和配置。
1. 准备Linux环境
准备3台Linux主机,按照下面的步骤在每台主机上执行一遍,我的是如下结果:
master:192.168.36.129
slave1:192.168.36.131
slave2:192.168.36.132
以master节点root身份为例:
1.1关闭防火墙
关闭Selinux:
临时关闭:# setenforce 0
永久关闭:# vi /etc/selinux/config
修改其中的参数:SELINUX=disabled,按Esc:qw保存退出。关闭iptables:
安装服务(选做):# yum -y install iptables-services
临时关闭:# systemctl stop firewalld.service
永久关闭:# systemctl disable firewalld.service
(之后操作默认你的三台主机可以ping 通 baidu.com(即网络已经配好,主机名已经配好
方式1:hostnamectl set-hostname master
方式2:vi /etc/hostname
清空内容后写入:master))
1.2主机名和IP的映射关系
此处建议XShell同时操作三台虚拟机
编辑hosts配置文件:# vi /etc/hosts,追加3行:
192.168.36.129 master
192.168.36.130 slave1
192.168.36.131 slave2
每个主机都要测试主机名是否可用:
ping master
ping slave1
ping slave2
1.3三台主机两两免密码登录
-
使用ssh-keygen工具生成秘钥对:
ssh-keygen -t rsa私钥:Your identification has been saved in /root/.ssh/id_rsa. 公钥:Your public key has been saved in /root/.ssh/id_rsa.pub. -
将生成的公钥发给三台主机:master、slave1、slave2:
ssh-copy-id -i /root/.ssh/id_rsa.pub root@master ssh-copy-id -i /root/.ssh/id_rsa.pub root@slave1 ssh-copy-id -i /root/.ssh/id_rsa.pub root@slave2 -
测试秘钥认证是否成功:
ssh root@master ssh root@slave1 ssh root@slave2
直接回车即可登录,不用输入密码,说明免密码登录配置成功。
2. 安装JDK
我这里JDK选择的是jdk1.8.0_271即:jdk-8u271-linux-x64.tar.gz
2.1上传JDK
方式1:通过上述共享文件夹上传到Linux中
方式2:通过linux自带的浏览器下载(左上角应用程序中)
2.2解压JDK安装包
以下所下载的文件均放到/home/hadoop/(主目录)中
tar -zxvf jdk-8u271-linux-x64.tar.gz
2.3配置Java环境变量
在主目录下vi .bash_profile
在文件末尾追加如下内容:
JAVA_HOME=/home/hadoop/jdk1.8.0_271
export JAVA_HOME
PATH=$JAVA_HOME/bin:$PATH
export PATH
按Esc:wq保存退出,使用source命令使配置文件立即生效:
source .bash_profile
2.4测试JDK是否安装成功
java -version
3. 安装Hadoop全分布模式
我这里Hadoop选择的是hadoop-3.1.3即:hadoop-3.1.3.tar.gz
3.1 上传Hadoop
方式1:通过上述共享文件夹上传到Linux中
方式2:通过linux自带的浏览器下载(左上角应用程序中)
3.2 解压Hadoop安装包
将下载的文件放到/home/hadoop/(主目录)中
tar -zxvf hadoop-3.1.3.tar.gz
3.3 配置Hadoop环境变量(3台主机上都做一遍)
方式1:可以Xshell批量操作。
方式2:也可以master做完分发到slave1和slave2中。(这里采用方式2)
vim .bash_profile
在文件末尾追加如下内容:
HADOOP_HOME=/home/hadoop/hadoop-3.1.3
export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
按Esc:wq保存退出,使用source命令使配置文件立即生效:
source .bash_profile
3.4 配置Hadoop全分布模式的参数
进入到/home/hadoop/hadoop-3.1.3/etc/hadoop
(1)配置hadoop-env.sh文件:
vim hadoop-env.sh
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/home/hadoop/jdk1.8.0_271
(2)配置hdfs-site.xml文件:
vim hdfs-site.xml
<configuration><property>
<name>dfs.replication</name>
<value>2</value>
</property><property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
(3)配置core-site.xml文件:
mkdir /home/hadoop/hadoop-3.1.3/tmp
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.36.129:9000</value>
</property><property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.7.3/tmp</value>
</property>
</configuration>
(4)配置mapred-site.xml文件:
将模板文件mapred-site.xml.template拷贝一份重命名为mapred-site.xml然后编辑:
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(5)配置yarn-site.xml文件:
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property><property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
(6)配置slaves文件:
vim slaves
slave1
slave2
3.5 对NameNode进行格式化
hdfs namenode -format
3.6 分发安装包给从节点
将master上配置好的Hadoop安装目录分别复制给两个从节点slave1和slave2,并验证是否成功。
cd /home/hadoop
scp -r hadoop-3.1.3/ root@slave1:/home/hadoop/
scp -r hadoop-3.1.3/ root@slave2:/home/hadoop/
3.7 在master上启动Hadoop全分布模式
start-all.sh
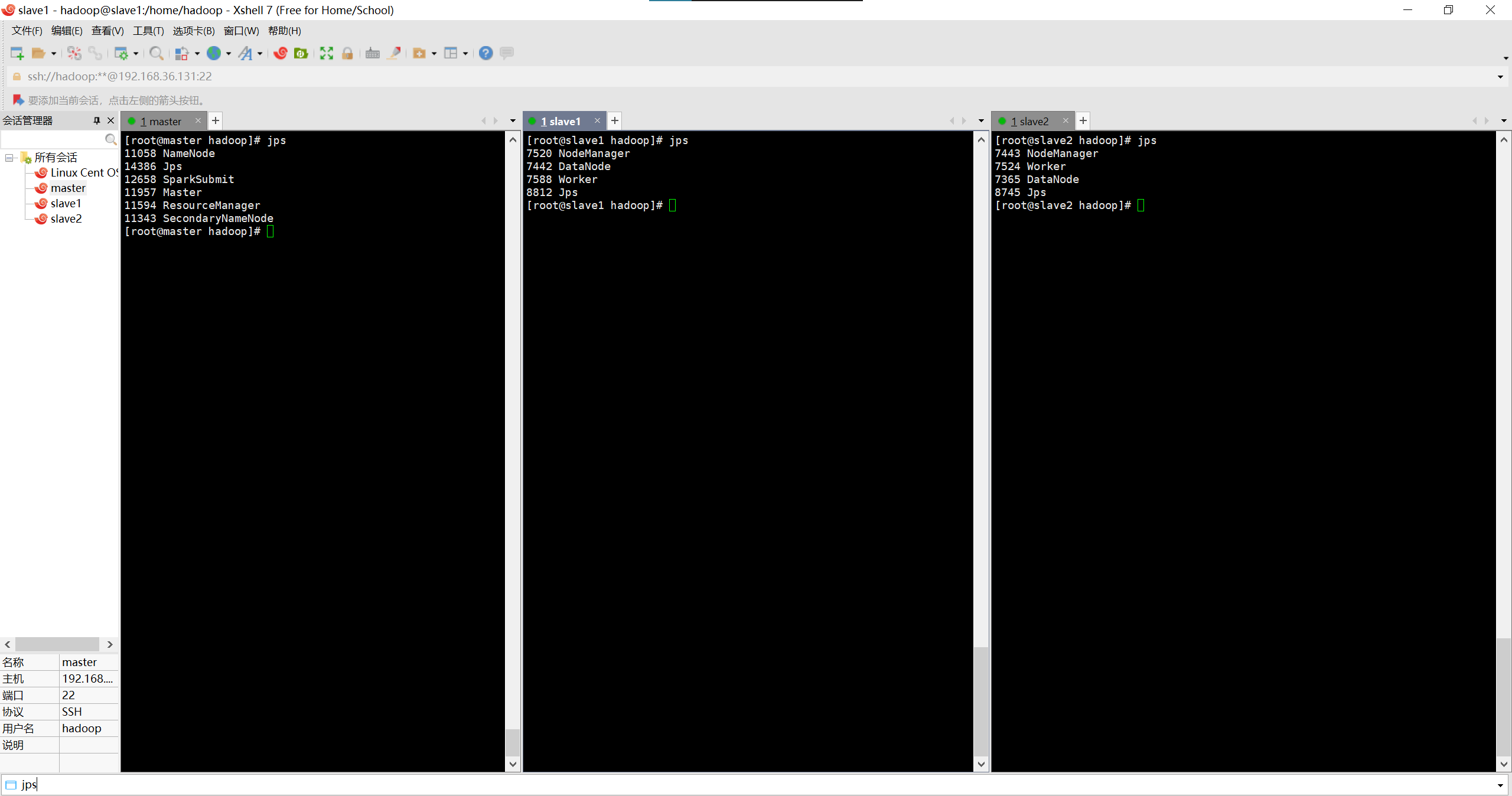
启动成功后,使用jps命令查看各个节点上开启的进程:

stop-all.sh 可以关闭集群
4. 安装VScode
我安装的版本是:code-1.52.1-1608137084.el7.x86_64.rpm
安装命令:
rpm -ivh code-1.52.1-1608137084.el7.x86_64.rpm
此命令中各选项参数的含义为:
-i:安装(install);
-v:显示更详细的信息(verbose);
-h:打印 #,显示安装进度(hash);
5. 安装Python3.6.5
我这里使用的是Python3.6.5.tgz
首先进入主目录
mkdir python3.6
cd python3.6
文件放入此文件夹后解压:
tar -zxvf Python-3.6.5.tgz
安装依赖:
yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc
进入解压后的目录:
cd /home/hadoop/Python-3.6.5
编译安装,依次执行以下三行代码:
./configure --prefix=/usr/local/python3
其中--prefix是Python的安装目录makemake install
出现下图则安装成功!!

建立软连接:
ln -s /usr/local/python3/bin/python3 /usr/bin/python3
ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3
//输入python3,出现下图所示

配置环境变量:
进入主目录后输入:
vim .bash_profile
在后面插入:
PYSPARK_PYTHON=python3
export PYSPARK_PYTHON
PATH=$PYSPARK_PYTHON/bin:$PATH
export PATH
source .bash_profile使配置生效即可。
6. 安装Spark
我们先在master节点上配置好参数,再分发给两个从节点slave1和slave2。
6.1 上传Spark安装包
我使用的是spark-2.3.4-bin-hadoop2.7.tgz
6.2 解压Spark安装包
在主目录中
mkdir spark2
cd spark2
文件放入此文件夹后解压
tar -zxvf spark-2.3.4-bin-hadoop2.7.tgz
6.3 配置Spark环境变量(三台机器都做一遍)
进入主目录后输入:
vim .bash_profile
在后面插入:
SPARK_HOME=/home/hadoop/spark2/spark-2.3.4-bin-hadoop2.7
export SPARK_HOME
PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
export PATH
注意:由于Spark的命令脚本和Hadoop的命令脚本有冲突(比如都有start-all.sh和stop-all.sh等),
所以这里需要注释掉Hadoop的环境变量,添加Spark的环境变量:
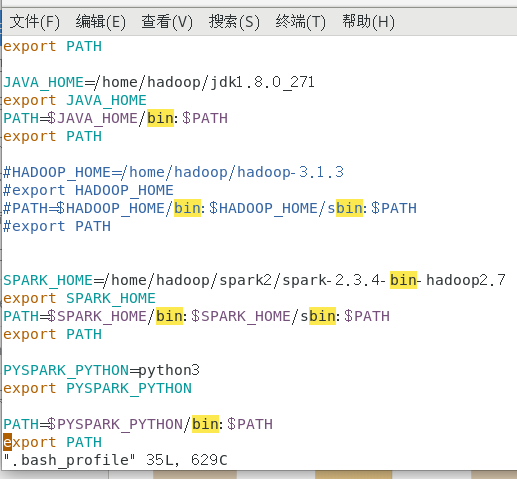
source .bash_profile使配置生效即可。
6.4 配置Spark参数
cd /home/hadoop/spark2/spark-2.3.4-bin-hadoop2.7/conf/
(1) 配置spark-env.sh文件:
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
export JAVA_HOME=/home/hadoop/jdk1.8.0_271
export HADOOP_HOOME=/home/hadoop/hadoop-3.1.3
export HADOOP_CONF_DIR=/home/hadoop/hadoop-3.1.3/etc/hadoop
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORKER_MEMORY=1G
(2) 配置slaves文件:
cp slaves.template slaves
vim slaves
追加两行:
slave1
slave2
6.5 分发安装包给从节点
将master上配置好的Spark安装目录分别复制给两个从节点slave1和slave2,并验证是否成功。
scp -r /home/hadoop/spark2/spark-2.3.4-bin-hadoop2.7/ root@slave1:/home/hadoop/spark2
scp -r /home/hadoop/spark2/spark-2.3.4-bin-hadoop2.7/ root@slave2:/home/hadoop/spark2
6.6 在master节点上启动Spark全分布模式
首先启动hadoop由于注释了hadoop的配置信息,所以需要进入hadoop-3.1.3/sbin目录下使用指令:
./start-all.sh
先启动hadoop
之后启动spark
start-all.sh
关闭的话是先关闭spark
stop-all.sh
再去hadoop-3.1.3/sbin目录下使用指令:
./stop-all.sh
即可。
那么我们开启hadoop、spark集群

在本机可以登录50070查看hdfs文件系统
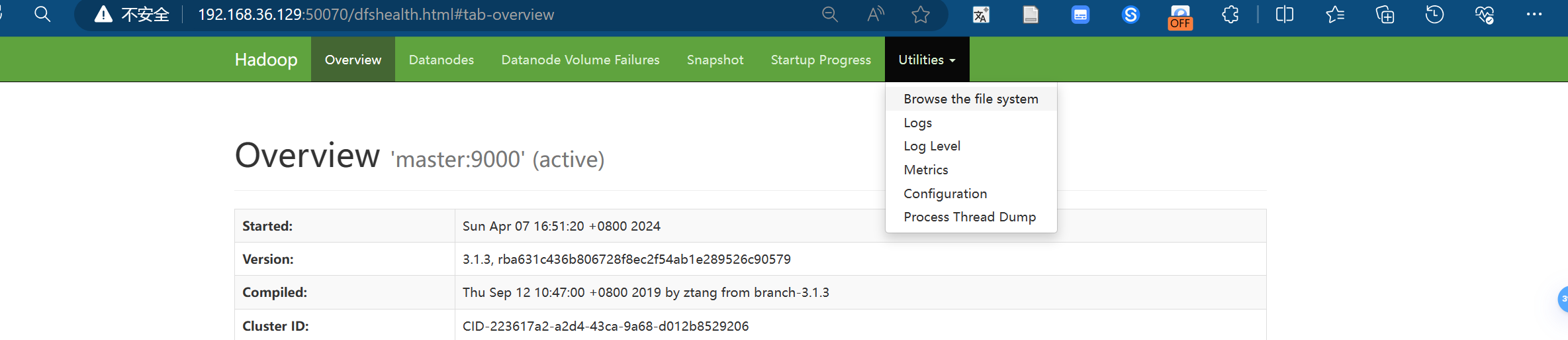
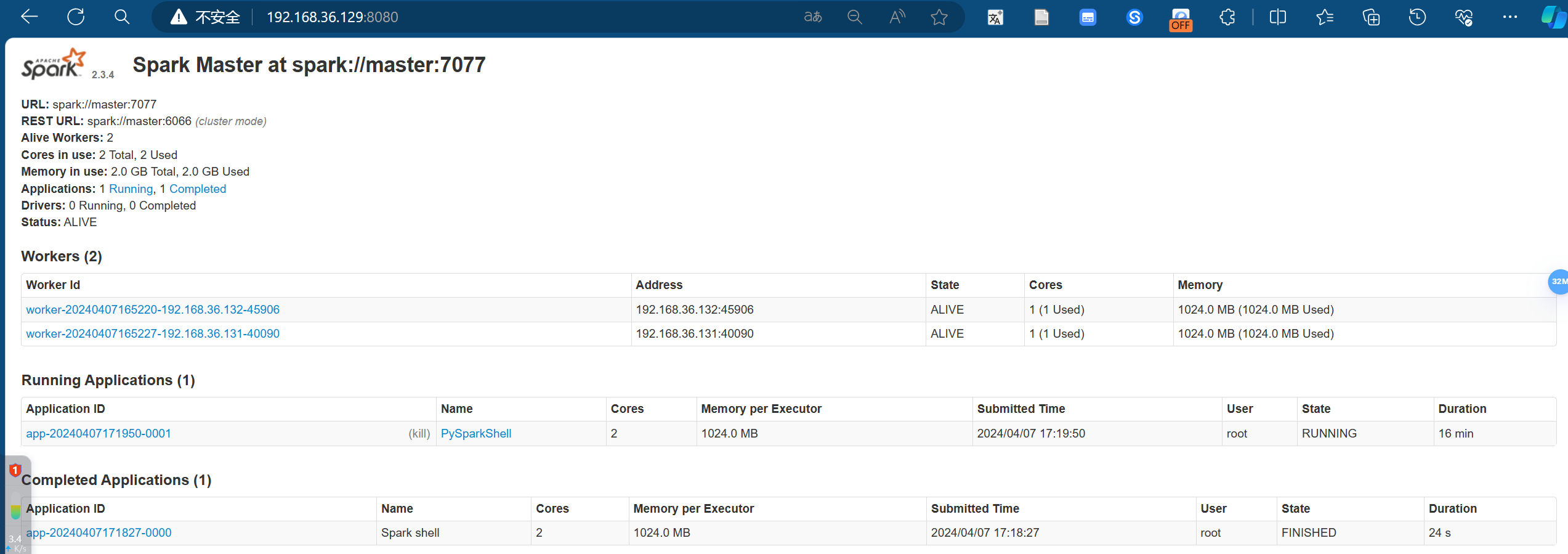
在本机可以登录8080端口查看spark集群运行情况!!
7. 启动pyspark分布式运行决策树模型
参考pyspark在机器学习中实战小练中的内容实现决策树代码
7.1 首先上传数据集:
创建hdfs文件夹:
hdfs dfs -mkdir -p /user/root
先把数据集下载到linux上再上传数据集adult.csv到hdfs中:
hdfs dfs -put ./adult.csv /user/root/
7.2 启动集群:
以集群的方式启动pyspark:
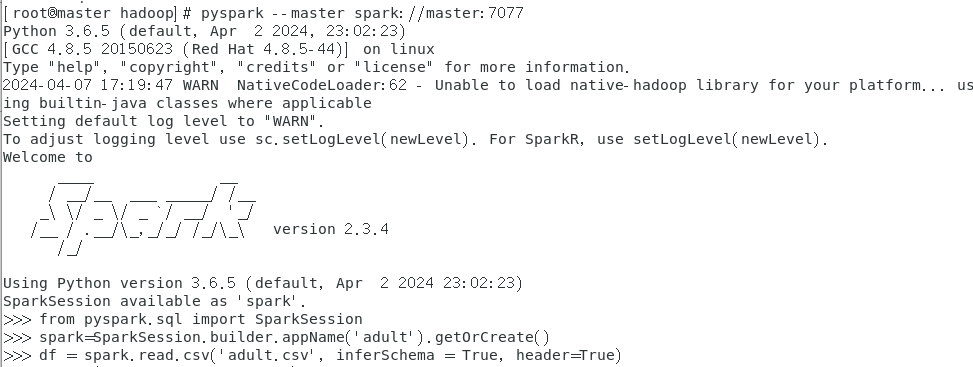
pyspark --master spark://master:7077
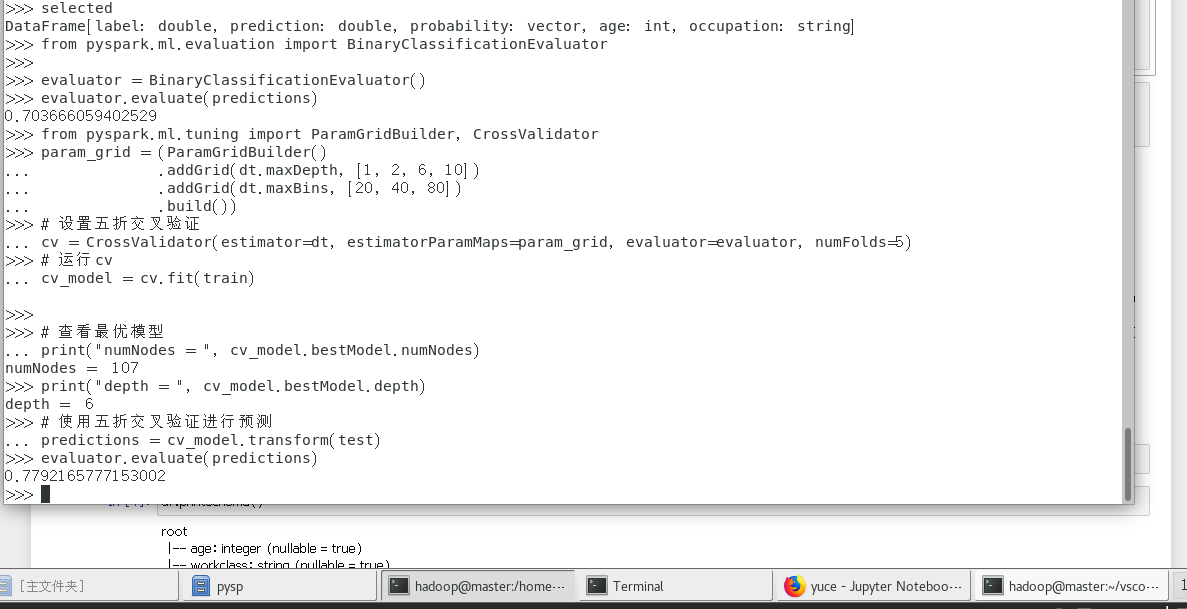
结果如图
接着输入代码以下仅展示部分代码运行结果:
(数据类型展示)

(抽取需要的信息)

(创建决策树模型)
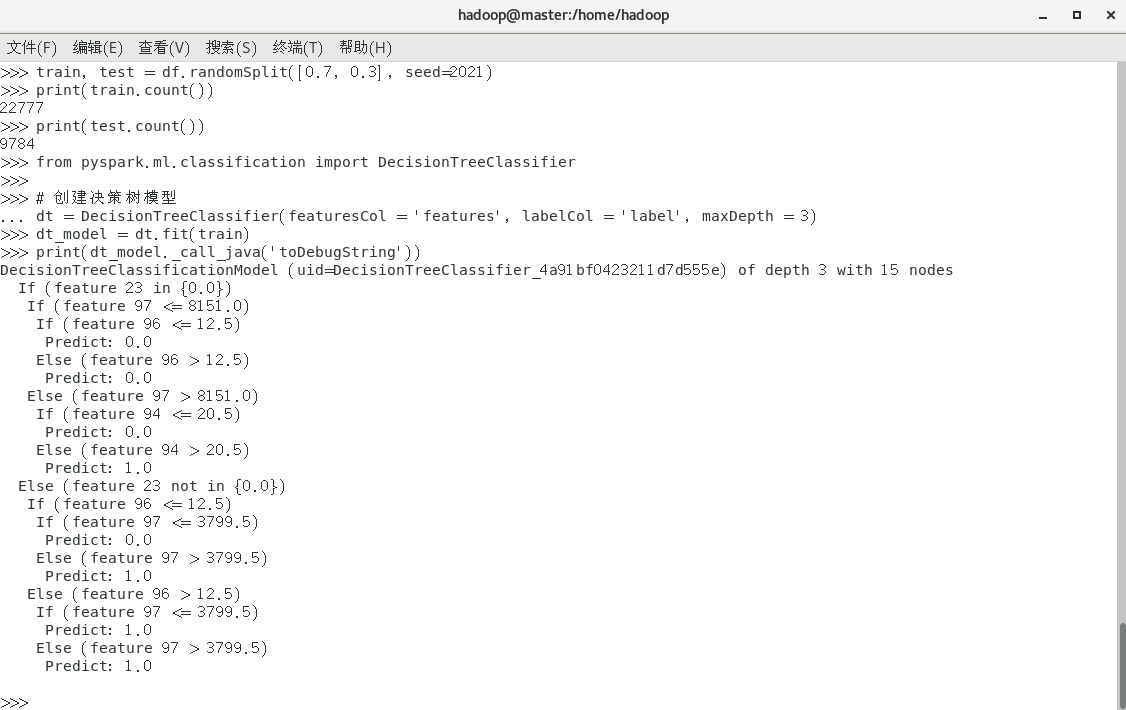
(运行结果)
jps
效果如图:

大功告成啦!!!!!!!!!